
How to Choose the Right Approach to Creating an AI Test Project
This article will walk you through different approaches to creating artificial intelligence (AI)-based smart systems.
Today, thanks to the available libraries, as well as a better understanding of the approaches and terminology, you can make an AI test project yourself and accelerate the development of your business and/or digital product. As such, the article will be useful for project managers, product owners, and everyone who is interested in the implementation of AI.
In the summer of 2020, OpenAI introduced the largest language model ever trained – Generative Pre-trained Transformer 3 (GPT-3). In addition to the usual machine translation and answering questions, GPT-3 can create almost human-level text content, write tweets or short articles.
To achieve the effect of a “thinking” system of the model, it took 600 GB of Internet texts and 175 billion parameters. In contrast, the human brain needs much less data to do the same thing as a machine. When creating a post on a social network, a person does not analyze thousands of other texts, but simply constructs from their own vocabulary of 75-80 thousand words.
So, is it fair to say that GPT-3 can think and analyze? If you focus on behavior only, the actions of AI-based software appear to be quite intelligent. It seems that we’re getting closer to creating a mind similar to that of humans. If not for one fact: human intelligence is not determined only by behavior. We will be intelligent just sitting in the dark and idly thinking about the problem.
Traditional machine learning (ML) is evolving through the accumulation of more and more data and the increase in processing power. But this process is not endless, and if we want to create truly intelligent systems, we need to work more closely with neuroscientists.
Let’s Get Into Terminology First
Artificial Intelligence
Artificial Intelligence (AI) is a broad concept that includes technologies and theories for creating smart systems. Machine Learning is an AI subgroup that creates algorithms for self-learning of artificial models. The goal of ML is to teach the system to solve complex problems such as recognize given objects, recommend music or movies, etc.
Deep Learning is a subsection of ML. It helps structure algorithms in layers to create an artificial neural network that adapts and learns from huge amounts of data. A trained neural network can solve complex problems. For example, based on genre, budget, and cast data, it can predict how much a movie will make after the release.
Data Science refers to data analysis. It combines statistics, mathematics, programming, and domain expertise to extract useful insights from big and small data. Any business accumulates information pertaining to user behavior, a number of sales and transactions, seasonal fluctuations, and so on. With the help of Data Science, this data set can be analyzed and insights can be obtained that can move the business beyond the competition.
When AI is indispensable
AI is taking up more and more space on new job listings, according to LinkedIn. Many positions require an extended knowledge of AI more than ever before, and it seems that soon no project will be complete without Data Science.
The general goal of machine learning is to teach the system to solve complex problems. Here’re the examples:
- recognize human faces or other objects;
- understand speech;
- drive a car (Google Self-Driving Car);
- diagnose diseases by symptoms;
- understand the tone of voice or meaning of the text;
- make decisions about the risks of issuing a loan;
- predict sales and demand for city bicycles;
- advise products, books (Amazon), movies (Netflix), music (Spotify);
- act as a personal assistant or secretary (Siri, Android Now, Cortana).
The classical approach to AI helps accumulate and then use huge amounts of knowledge. For example, Google, thanks to a new machine learning model for Google Translate, has reduced the gap in translation accuracy to 85%.
The issue is that the increase in capacity will not continue indefinitely. If we simply scale up the current methods, we are faced with the limitations of the hardware, because the result requires more and more memory and power.
Google’s same success in translation is only possible thanks to the sheer amount of accumulated data. Over time, machine learning should take a new course. A different approach is needed for systems to become truly intelligent and self-learning.
Limitations of the classical approach
Traditional AI is built like a mathematical method: searching for patterns in large statistical datasets. The more data in the algorithm, the higher the output precision. The challenge is getting the right amount of labeled training data. And in many cases they simply do not exist. So, in theory, ML can be implemented even in beekeeping: create an algorithm to predict the most “productive” hives. But in practice, there is not enough information to get the result with the required degree of accuracy.
Artificial neural networks perform poorly with a small amount of data for training and fail to cope with problems when patterns in the data are constantly changing.
For example, if you add “noise” to the image, the car makes a mistake in assessing what is shown in the picture, confuses the road signs. And the person still recognizes the correct answer and does not even notice the difference in the images.
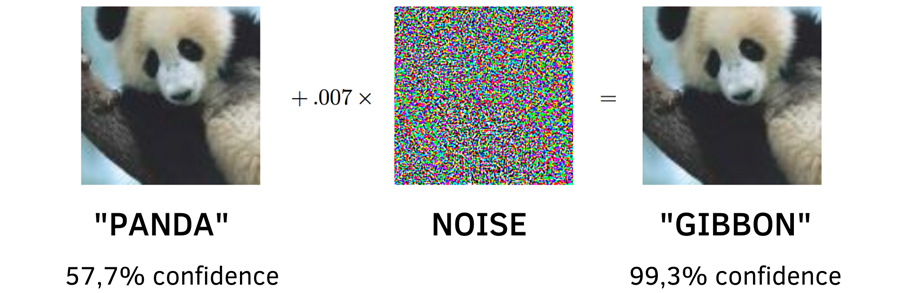
The creators of traditional artificial intelligence focus mostly on behavior: how to get the model to produce the correct or desired results after processing the input data. And rightly so, since machine learning is a tool for improving and automating business processes. But if we talk about intelligent systems, we need to look for additional ways.
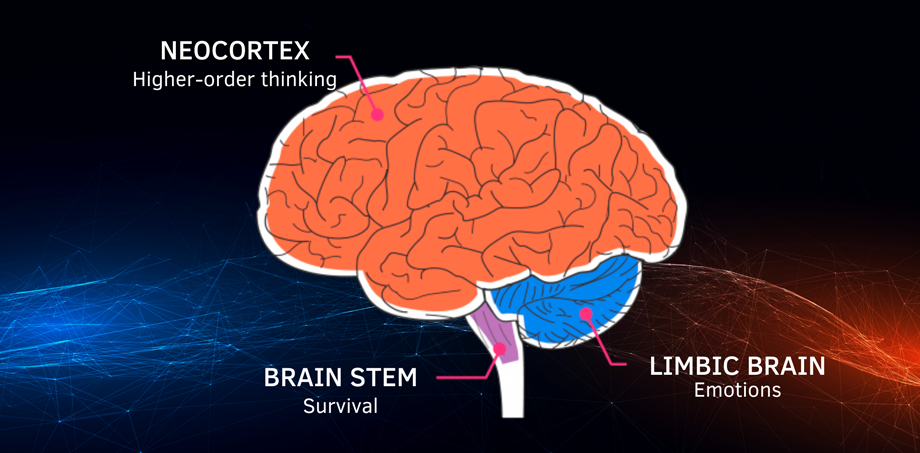
To build a thinking machine, let’s look at the part of the brain that is associated with intelligence in modern research. We are talking about the neocortex – a thin shell that covers both large hemispheres.
How natural intelligence works
The neocortex is the main and evolutionarily youngest part of the cerebral cortex. Every day, the human neocortex examines the structure of the world based on information passing through the senses, and it makes predictions every second – from the task of catching the ball to planning what time to get up to get to work on time.
Scientists have accumulated a lot of observations about the actions and reactions of the brain, but there is still no single theory that would explain the work of the human intellect. Such a holistic theory was presented by Jeff Hawkins in his book “On Intelligence: How a New Understanding of the Brain Will Lead to the Creation of Truly Intelligent Machines.”
In it, he argues that to create intelligent machines, you need to turn not only to mathematics but also to neurobiology. First, present a unified theory of how the brain works, and then create machine intelligence after the biological one.
With experience working at Intel and launching two of his own IT companies, Hawkins founded the startup Numenta. The new company focused on developing algorithms based on how the neocortex works.
What computer can and cannot do compared to human brain
The world is diverse, and it is amazing how a person learns all sorts of forms of the same concepts. Let’s take the everyday concept of a dog. In the brain, there is a general mental concept of “dog”, which helps to correctly recognize dogs of all breeds and sizes. Moreover, in order to form a general idea of the concept, a person does not need data arrays; 3-4 pictures are enough. This way of processing information is very different from the machine. According to Hawkins, neocortical memory has important properties that classical artificial intelligence lacks.
Here’re just few of them.
Our memories are auto-associative. The memory remembers and recognizes the object even with incomplete or distorted data. When you see an acquaintance in a crowd, partially closed by other people, the neocortex automatically completes a holistic image – and recognition occurs.
Object representations are stored in an invariant form. The neocortex retains the essence of ideas about the world around us, and not specific details. The brain transforms any sensory information into an invariant form, and then compares new data with it. Invariance helps to apply knowledge of past events to a new situation that is similar but not identical.
It is thanks to the invariant form of memories that it is enough for a person to see several dogs in order to later identify the dog among other objects, whereas a machine needs thousands of images in different variations to recognize it.
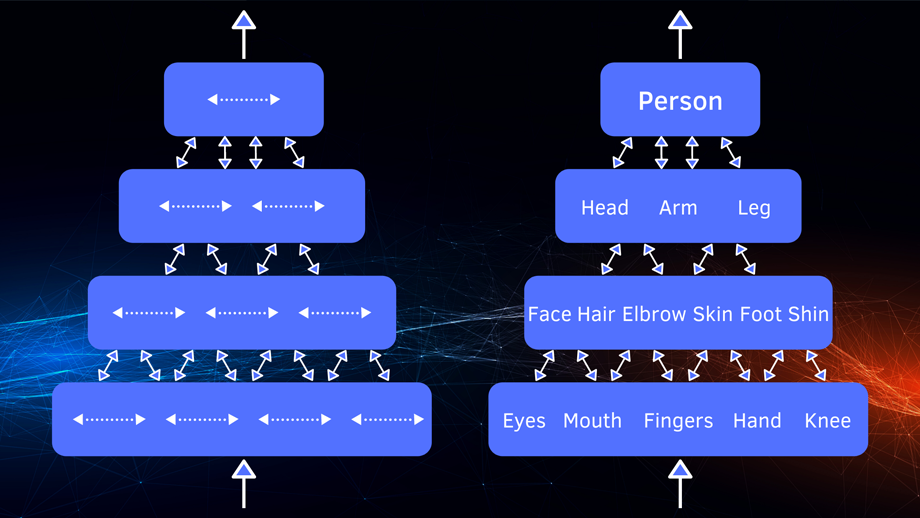
The data is arranged in a hierarchical order. It does not matter which sensor has received the information – the eye, nose, or ear because the information enters the brain in the form of impulses. Then the impulses excite the neurons of the cortex, stacked in hierarchical column layers. Layer by layer, information moves to higher levels of abstraction.
An example of hierarchical storage of information: At the lower levels, the neocortex stores data about small parts of the visual field, such as lines and angles, because the line is one of the main elements of the visual image. At the middle levels, lines and corners are redistributed into more complex components – curves and textures. The arc can be both the upper part of the steering wheel in the car, and the rim of a mug with tea. At higher levels, patterns are combined to represent higher-level objects such as faces, cars, or houses.
The brain does not learn a high-level object from scratch: the hierarchy allows a new object to inherit the already known properties of its components. For example, when we see a new word, we do not re-learn its letters or syllables. Hierarchical order, invariance, and auto-associativity help a person make accurate predictions about the world around him and recognize anomalies. In the real-time, the brain constantly predicts what we will see, feel, hear.
The neocortex generates predictions based on experience and then compares expectations with incoming information. When you walk to the door of your apartment, neurons fire before the senses can receive information. The brain knows what sensation will be in the fingers when touching the surface, what will be the resistance of the door, at what height the lock is located. When the predictions match reality, you will walk through the door without even realizing the instant check. However, if expectations are violated – the key turned too freely, an uncharacteristic sound, an unusual tactile sensation – they will instantly attract attention.
It is the ability of the brain to make assumptions about the future, not behavior, is the essence of intelligence, according to Hawkins. Therefore, Numenta uses the cortical memory-prediction model to create intelligent systems. Hawkins called this approach Hierarchical Temporal Memory (HTM).
A new way to train systems
Traditional programming has used rigid algorithms to solve specific problems, and the Hierarchical Temporal Memory model learns from the incoming sensor data stream. It is a machine intelligence framework based on the interconnections of neurons in the human cortex. Like a traditional neural network, HTM is trained on changing input data and is able to memorize sequences of patterns. The difference appears in the way of storage and playback.
The neurons of HTM are arranged in a multilayer column-like fashion, simulating the hierarchy of regions in the neocortex. The patterns learned at the lower levels of the hierarchy are used in various combinations at the higher levels.
The hierarchy reduces the time to train the model and the amount of memory required for operation. The system is able to analyze the data flow in real-time and distinguish between context. Just as the brain remembers, generalizes and predicts most of the time, so through the HTM model, it is possible to identify, remember, predict spatial and temporal patterns in the data stream.
The HTM model supports 6 properties required by any learning algorithm:
1. Sequential Learning
Ability to make predictions and answer the main question “What will happen next?” based on past experience. Any algorithm should make predictions not only in a static form but also in a temporal context.
2. Multiple Simultaneous Forecasts
Sometimes there is not enough data to predict events in the “real” world, so it is necessary to assume the highest probability. In other words, we will find out the probability of what the model predicted will happen.
3. Continuous learning
Streaming data in real-time changes frequently, and the algorithm must also be rebuilt for new inputs. In traditional ML, models are difficult to adapt without changes in data preparation.
4. Real-time training
It is valuable for streaming data when the algorithm remembers new patterns on the fly. HTM copes with this, but in ML you need to save new sequences and train the model again.
5. Resistance to noise
Real data often contains noise or unnecessary information. A good algorithm resists interference and recognizes junk data.
6. No need to tweak hyper-parameters every time
In traditional machine learning, model parameters are tuned for a specific task. When the task changes, you have to create a new algorithm or change it to another, and eventually reconfigure the hyper-parameters. In HTM, one model can solve problems of different kinds, so tuning hyperparameters takes much less time.
The first two points are performed by a traditional neural network, but starting from the third, HTM shows the best results. The cortical approach is especially needed where the model is required to predict, detect anomalies, classify, and target behavior. Based on Hawkins’ cortical theory, Numenta programmers build a framework and make it publicly available.
Final Thoughts
It is difficult to predict exactly what the research of Hawkins and other neuroscientists will turn out to be. When people invented microprocessors, they knew they were doing something important, but they did not foresee the advent of the Internet and mobile phones. If neuroscience becomes the basis for AI, it will lead to incredible transformations.
Stay tuned with Software Focus!